LLM(대규모 언어 모델, Large Language Model) 강화학습 과정
기본 모델 학습 (Pretraining)
인터넷, 책, 논문 등의 대량 텍스트 데이터를 사용해 지도학습(Supervised Learning)과 자기지도학습(Self-Supervised Learning) 을 수행합니다.
이 과정에서 모델은 단어, 문장, 문맥을 학습하고 기본적인 언어 능력을 갖추게 됩니다.
CLM 학습 참조
지도 미세조정 (Supervised Fine-tuning, SFT)
사람이 직접 라벨링한 데이터를 사용해 모델을 지도학습합니다.
예를 들어, 질문에 대한 적절한 답변을 사람이 작성하고 이를 모델이 학습하는 방식입니다.
질문과 답변을 모두 사람이 작성
DPO (Direct Preference Optimization)
기존의 RLHF(보상 학습을 통한 강화 학습, Reinforcement Learning with Human Feedback) 등의 접근법에 비해 더 간단하면서도 효과적인 결과를 얻습니다.
-
사용자 피드백 수집
모델이 생성한 다수의 답변 또는 출력물을 사용자(사람)에게 제시하고,
각 쌍(pair)에 대해 어떤 답변(출력물)이 더 바람직한지를 뜻하는 선호 데이터를 수집합니다. -
직접 최적화
선호 데이터가 나올 확률을 높이기 위한 손실함수 생성
-
파라미터 업데이트
손실함수를 이용해 파라미터 업데이트
보상 모델 학습 (Reward Model Training)
다수의 답변 후보를 생성한 후, 사람이 답변의 품질을 비교 평가합니다.
이 평가 데이터를 기반으로 보상 모델(Reward Model, RM)을 학습합니다.
보상 모델은 "어떤 답변이 더 좋은지"를 예측하는 역할을 합니다.
-
사람 또는 인공지능이 질문을 생성, 사람이 품질 측정 (0.0 ~ 1.0 으로 점수 부여)
-
질문+답변+품질을 이용해 보상모델 학습
"질문+답변" 이 보상 모델의 입력이 되고, "품질" 이 출력이 되어, 모델을 학습
강화학습 단계 (Reinforcement Learning, RLHF)
보상 모델을 활용해 라벨링을 자동화하고, 모델을 강화학습합니다.
대표적인 방법이 Proximal Policy Optimization (PPO) 입니다.
모델이 여러 개의 답변을 생성하면 보상 모델이 점수를 매기고, 이 점수를 기반으로 모델이 더 나은 답변을 생성하도록 업데이트합니다.
PPO 는 아래에서 별도 설명
추가 미세조정 및 평가 (Fine-tuning & Evaluation)
사람이 직접 라벨링한 데이터를 사용해 다시 모델을 지도학습할 수도 있습니다.
이후, 사람이 질문을 입력해 답변을 평가합니다.
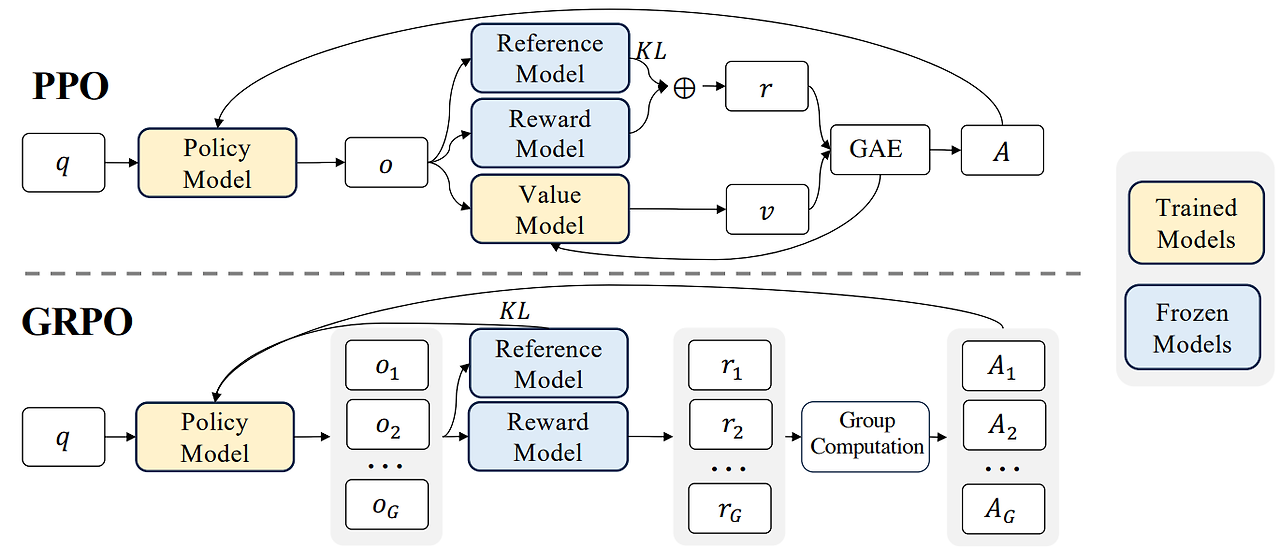
PPO (Proximal Policy Optimization)
Policy Model (정책 모델):
- 에이전트의 행동을 결정하는 핵심 모델입니다
- 입력으로 상태(q)를 받아 행동(o)을 출력합니다
- 환경과 직접 상호작용하여 행동을 선택하는 역할을 합니다
- 학습 여부: LLM 에서 정책 모델 자체가 인공지능 모델이 되며, 학습의 목표입니다.
Reference Model (참조 모델):
- 이전 정책의 상태를 저장하는 모델입니다
- 현재 정책이 이전 정책에서 너무 많이 벗어나지 않도록 제한하는 역할을 합니다
- KL divergence를 통해 정책 변화를 제어합니다
- 학습 여부: 정책 모델과 동일한 상태로 시작하며, 고정된 모델이 될수도, 일정주기마다 업데이트(정책모델 복사)되기도 합니다.
Reward Model (보상 모델):
- 에이전트의 행동에 대한 보상을 계산하는 모델입니다
- 행동의 적절성을 평가하고 수치화된 보상(r)을 제공합니다
- 학습의 방향을 결정하는 중요한 신호를 생성합니다
- 학습 여부: 일반적으로 고정된 모델로 사용됩니다.
Value Model (가치 모델):
- 현재 상태의 기대 보상을 추정하는 모델입니다
- 미래에 얻을 수 있는 보상의 현재 가치(v)를 계산합니다
- 정책의 성능을 평가하고 개선 방향을 제시하는 역할을 합니다
- 학습 여부: 학습 가능한 모델로, 실제 에이전트의 보상과 예상 보상 간의 차이를 최소화하도록 최적화됩니다.
GRPO (Group Relative Policy Optimization)
DeepSeek 에 적용된 강화학습 방식입니다.
Value 모델을 제거하고, 보상모델을 매우 단순화했습니다.
# https://huggingface.co/docs/trl/main/en/grpo_trainer
# pip install trl
from datasets import load_dataset
from trl import GRPOConfig, GRPOTrainer
dataset = load_dataset("trl-lib/tldr", split="train")
# Define the reward function, which rewards completions that are close to 20 characters
def reward_len(completions, **kwargs):
return [-abs(20 - len(completion)) for completion in completions]
training_args = GRPOConfig(output_dir="Qwen2-0.5B-GRPO", logging_steps=10)
trainer = GRPOTrainer(
model="Qwen/Qwen2-0.5B-Instruct",
reward_funcs=reward_len,
args=training_args,
train_dataset=dataset,
)
trainer.train()