Table of Contents
Hadoop Cluster 구성하기(with Spark)
기본 방향
-
EC2 인스턴스 하나 생성
-
공통설정 적용
-
생성한 인스턴스를 이미지로 저장
-
이미지에서 인스턴스 추가 생성
최초 인스턴스를 master 로 하고,
3개의 인스턴스를 추가로 생성하여 data node 로 설정
EC2 인스턴스 하나 생성
OS 는 Ubuntu 20.04 로 합니다.
인스턴스는 c5a.large 로 선택합니다.(메모리 4기가)
t계열 인스턴스보다 2배정보 비싸지만,
지속적으로 cpu 를 사용하는 로그 시스템에서 t계열 인스턴스는 위험합니다.
보안그룹은 이름을 hadoop 을 설정하고,
22번 포트만 0.0.0.0 에서 접근이 가능하도록 설정합니다.
생성한 인스턴스로 로그인합니다.
공통설정 적용
JDK 1.8 설치
sudo apt-get update
sudo apt-get install openjdk-8-jdk
java -versionhadoop 계정생성
sudo groupadd -g 10000 hadoop
sudo useradd -m -s /bin/bash -g hadoop -u 10000 hduserhadoop 계정에 sudo 권한 부여
# 에디터 vim 선택
sudo update-alternatives --config editor
sudo visudo
......
hduser ALL=(ALL) NOPASSWD:ALL
......hadoop 설치
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.2.3/hadoop-3.2.3.tar.gz
sudo tar xvfz hadoop-3.2.3.tar.gz -C /usr/local/
sudo chown -R hduser:hadoop /usr/local/hadoop-3.2.3/Spark 설치
wget https://dlcdn.apache.org/spark/spark-3.2.1/spark-3.2.1-bin-hadoop3.2.tgz
sudo tar xvfz spark-3.2.1-bin-hadoop3.2.tgz -C /usr/local/
sudo chown -R hduser:hadoop /usr/local/spark-3.2.1-bin-hadoop3.2/hadoop 계정 환경설정
sudo su - hduservi ~/.bashrc
......
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop-3.2.3/
export SPARK_HOME=/usr/local/spark-3.2.1-bin-hadoop3.2/
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin/:$HADOOP_HOME/sbin:$SPARK_HOME/bin:$SPARK_HOME/sbin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$HADOOP_HOME/lib/native
......
exit
sudo su - hduser예제 실행해 보기
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.3.jar wordcount $HADOOP_HOME/LICENSE.txt ~/output/
cat ~/output/part-r-*hadoop 설정
sudo su - hduser
vi $HADOOP_HOME/etc/hadoop/core-site.xml
......
## <configuration> </configuration> 사이에 입력
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
......vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml
......
## <configuration> </configuration> 사이에 입력
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>data01:9868</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hduser/hadoop/hadoopdata/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hduser/hadoop/hadoopdata/hdfs/datanode</value>
</property>
......vi $HADOOP_HOME/etc/hadoop/yarn-site.xml
......
## <configuration> </configuration> 사이에 입력
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
......vi $HADOOP_HOME/etc/hadoop/mapred-site.xml
......
## <configuration> </configuration> 사이에 입력
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
......vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh
......
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
......vi $HADOOP_HOME/etc/hadoop/workers
-------------------
data01
data02
data03
-------------------vi $HADOOP_HOME/etc/hadoop/masters
-------------------
master
-------------------spark 설정
vi $SPARK_HOME/conf/slaves
-------------------
data01
data02
data03
-------------------vi $SPARK_HOME/conf/spark-env.sh
-------------------
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export SPARK_MASTER_HOST=master
export HADOOP_HOME=/usr/local/hadoop-3.2.3/
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
-------------------비밀번호 없는 ssh 로그인 허용
sudo su - hduser
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keysssh localhost생성한 인스턴스를 이미지로 저장
hadoop-spark 라는 이름으로 이미지를 생성합니다.
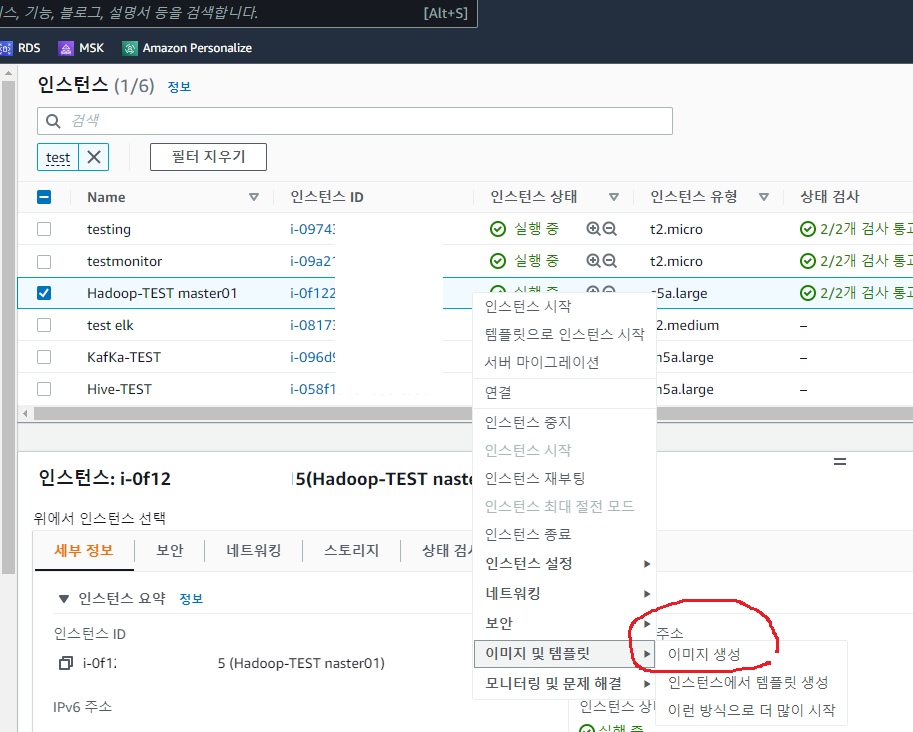
이미지 생성에는 몇분의 시간이 걸립니다.
인스턴스 추가생성
위에서 저장한 이미지로 인스턴스를 3개 생성합니다.
인스턴스는 c5a.large 로 선택합니다.(메모리 4기가)
보안그룹을 위에서 생성한 hadoop 으로 선택해 줍니다.
호스트파일을 수정합니다.
인스턴스의 프라이빗 IPv4 주소를 입력해 줍니다.
sudo su - hduser
sudo vi /etc/hosts
-------------------
172.31.7.69 master
172.31.7.54 data01
172.31.6.110 data02
172.31.2.208 data03
-------------------정상 접속을 확인합니다.
ssh master
ssh data01
ssh data02
ssh data03호스트파일을 복사해 줍니다.
cat /etc/hosts | ssh data01 "sudo sh -c 'cat >/etc/hosts'"
cat /etc/hosts | ssh data02 "sudo sh -c 'cat >/etc/hosts'"
cat /etc/hosts | ssh data03 "sudo sh -c 'cat >/etc/hosts'"보안그룹 수정
클러스터간 트래픽을 허용하도록 보안그룹을 수정해 줍니다.
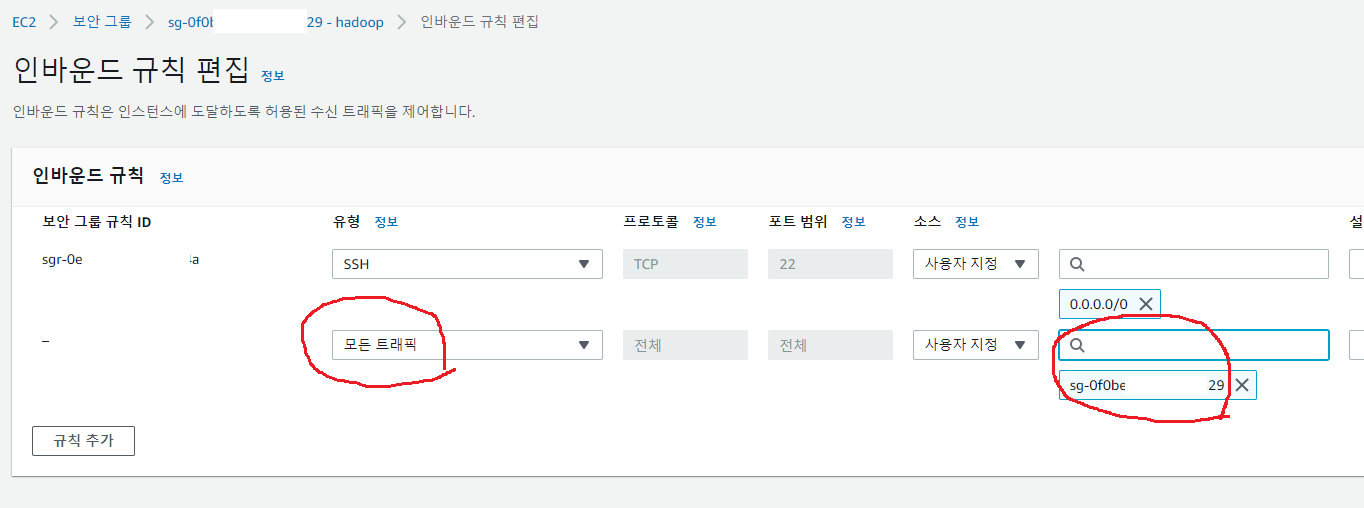
hadoop 보안그룹명을 소스로 지정해 줍니다.
클러스터 시작하기
네임노드 포멧
sudo su - hduser
hdfs namenode -formatstart-dfs.sh
......
Starting namenodes on [master]
Starting datanodes
Starting secondary namenodes [data01]master, data01, data02, data03 이 실행된 것을 확인할 수 있습니다.
ssh master
jps
3125 NameNode
3420 Jps
exit
ssh data01
jps
3280 SecondaryNameNode
3396 Jps
3119 DataNode
exit
ssh data02
jps
1113 Jps
975 DataNode
exit
ssh data03
jps
1113 Jps
975 DataNode
exit폴더 생성을 테스트 합니다.
hadoop fs -mkdir /test
hadoop fs -ls /hdfs dfsadmin -reportYarn 실행
start-yarn.shssh master
jps
4050 Jps
3125 NameNode
3766 ResourceManager
exit
ssh data01
jps
3280 SecondaryNameNode
3825 NodeManager
4031 Jps
3119 DataNode
exit
ssh data02
jps
3777 NodeManager
2914 DataNode
3980 Jps
exit
ssh data03
jps
3588 Jps
3384 NodeManager
2909 DataNode
exityarn node -list
Total Nodes:3
Node-Id Node-State Node-Http-Address Number-of-Running-Containers
data01:41077 RUNNING data01:8042 0
data02:42445 RUNNING data02:8042 0
data03:39255 RUNNING data03:8042 0Yarn 테스트
hadoop fs -put $HADOOP_HOME/LICENSE.txt /test/
yarn jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.3.jar wordcount hdfs:///test/LICENSE.txt /test/output
hadoop fs -text /test/output/*Spark Shell 실행하기
spark-shell --master yarn
......
scala> :quit클러스터 종료하기
stop-yarn.sh
stop-dfs.sh