Table of Contents
Elasticsearch 역색인(Inverted Index)
처음 보았을 땐 그런가보다 했는데, 이게 Elasticsearch 의 알파이자 오메가입니다.
역색인(Inverted Index)
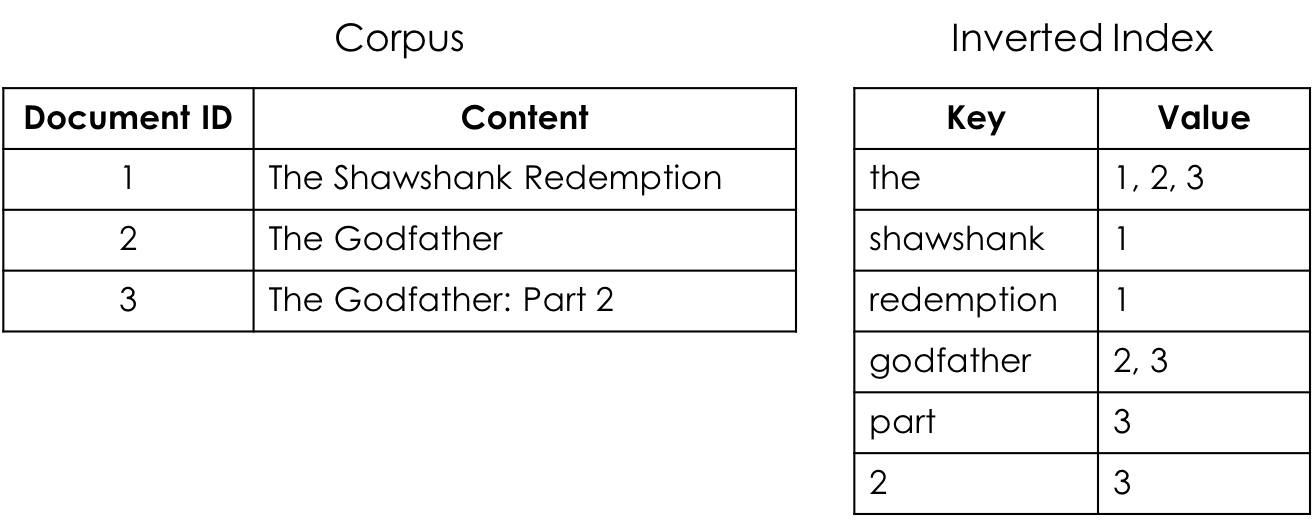
기존의 인덱스 생성방식이 문서를 기준으로 문서에 등장하는 키워드를 관리하는 방식이었는데 이것을 뒤집는겁니다.
반대로 키워드를 기준으로 키워드가 등장하는 문서를 관리하는 방식입니다.
장점
문서가 수천만이 넘더라도 키워드가 등장하는 문서의 수가 적다면 엄청나게 빠른 속도로 검색이 이루어지게 됩니다.
간단히 웹로그에서 clientip 를 키워드에 등록하게 되면, 수천만 수억개의 로그 속에서 특정 사용자의 로그를 빠르게 추적할 수 있게 됩니다.
단점
반대로 대다수의 문서에서 등장하는 단어라면 인덱스 생성의 장점은 사라지고 오히려 더 속도가 떨어지게 됩니다.
영어 문서의 경우 자주 등장하는 단어(a, the, and 등등) 는 인덱스로 관리해도 속도향상의 장점은 없고 오히려 느려지게 됩니다.
그래서 Elasticsearch 에서는 불용어(stopword) 로 등록하고 인덱스에서도 제거하고 검색어에 등장해도 무시하게 설정되어 있습니다.
어떻게 Elasticsearch 를 이용할 건가
인덱스에 넣을 단어와 넣지 말아야 할 단어, 그리고 불용어로 등록해서 검색어로 입력되어도 무시되도록 해야할 단어가 정해집니다.
또, 불용어까지는 아니어도 인덱스에서만 배제하면 좋는 단어도 있을겁니다.
장기간의 웹로그를 통계용도로 사용하면 느릴 수밖에 없는 이유가 나오네요.