Table of Contents
DeepSeek R1 로컬(PC)에서 실행하기
Ollama 설치
with cmd:
.\OllamaSetup.exe
# .\OllamaSetup.exe /DIR=D:\OllamaApp
with powershell:
Start-Process -FilePath ".\OllamaSetup.exe"
# Start-Process -FilePath ".\OllamaSetup.exe" -ArgumentList '/DIR=D:\OllamaApp' -Wait도스창에서 설치된 것을 확인합니다.
ollama -vDeepSeek R-1 설치
- Ollama를 실행한 뒤 Models 탭으로 이동
- deepseek 검색
-
deepseek-r1 다운로드
ollama run deepseek-r1:8b # ollama run deepseek-r1:1.5b
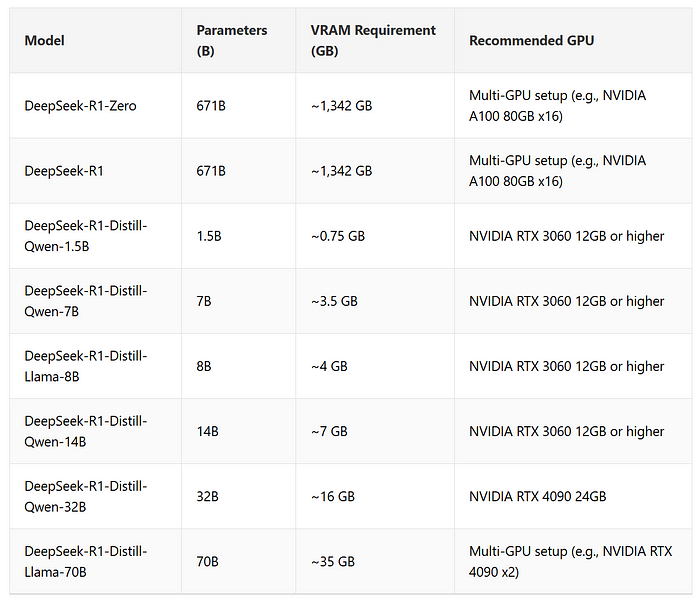
필요한 GPU
추가 학습된 AI 다운로드
공식적으로 배포되는 AI 는 한국어를 잘 지원하지 않는다.
한국어 학습을 추가로 시켜준 AI 도 배포되고 있는 것이 있으니 찾아서 다운받자.
인터페이스 개선
한국어 자체적으로 추가학습
아래 내용은 구글링만 한 것으로 실제 테스트 된 내용이 아닙니다
하드웨어 준비 (AWS)
p4d.24xlarge 또는 p5
GPU: NVIDIA A100 8개 (80GB 각 GPU)
CPU: 고성능 프로세서
RAM: 최소 512GB
스토리지: 최소 2TB (데이터셋 및 모델 크기 고려)# 기본 설치
sudo apt update
sudo apt install -y build-essential git wget
# GPU 드라이버 설치 (CUDA 11.8 예제)
wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda_11.8.0_520.61.05_linux.run
sudo sh cuda_11.8.0_520.61.05_linux.run예상비용 : 1600 ~ 6500달러
학습 프레임워크 설치
python3 -m venv venv
source venv/bin/activate
pip install --upgrade pip
pip install torch torchvision transformers datasets tqdm konlpy데이터셋 준비
pip install konlpy
# KoGPT 데이터 다운로드 (링크 확인 필요)
wget <KoGPT 데이터셋 URL> -O /path_to_dataset/kogpt_dataset.json전처리
from konlpy.tag import Mecab
import json
mecab = Mecab()
def preprocess_data(filepath):
with open(filepath, 'r') as file:
raw_data = json.load(file)
processed_data = []
for entry in raw_data:
korean_text = entry['text'] # 데이터셋 구조에 맞게 수정
tokenized = mecab.morphs(korean_text)
processed_data.append(" ".join(tokenized)) # 공백으로 토큰 구분
return processed_data
processed_data = preprocess_data("/path_to_dataset/kogpt_dataset.json")
output_path = "/path_to_dataset/processed_kogpt.txt"
with open(output_path, 'w') as file:
file.write("\n".join(processed_data))ollama 모델을 다운로드
ollama pull <model-name>
# or
git clone https://github.com/Ollama/models.gitfrom transformers import AutoModelForCausalLM, AutoTokenizer
# Hugging Face Ollama 모델 로딩
model_path = "/path_to_model"
model = AutoModelForCausalLM.from_pretrained(model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path)
from transformers import pipeline
device_map = "auto" # GPU 메모리 자동 할당
model = model.half().to(device_map) # FP16으로 변환모델을 로컬 환경에 저장
# 예시 경로
models/my_model/
└── pytorch_model.bin
└── config.json
└── tokenizer.json모델 로드
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("ollama-model-directory")추가 학습 설정
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="./finetuned_model",
per_device_train_batch_size=8,
num_train_epochs=3,
save_steps=500,
evaluation_strategy="steps",
logging_dir="./logs",
learning_rate=5e-5,
fp16=True, # GPU FP16 지원
)from datasets import load_dataset
dataset = load_dataset("path/to/your-dataset")학습 실행
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset["train"],
eval_dataset=dataset["validation"],
tokenizer=tokenizer,
)
trainer.train()
trainer.save_model("./finetuned_model")
tokenizer.save_pretrained("./finetuned_model")모델 테스트
from transformers import pipeline
finetuned_model = pipeline("text-generation", model="./finetuned_model", tokenizer="./finetuned_model")
result = finetuned_model("안녕하세요. 오늘 날씨는")
print(result)ollama 모델로 재배포
ollama push <model-name> ./finetuned_model
https://huggingface.co/lightblue/DeepSeek-R1-Distill-Qwen-1.5B-Multilingual