Table of Contents
Spark 에서 Kafka Topic 읽어오기
플러그인 설치
IntelliJ 에서 Scala, Big Data Tools 을 설치한다.
Scala 버전 확인
spark-shell
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
22/04/16 09:45:23 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://ip-172-31-18-128.ap-northeast-2.compute.internal:4040
Spark context available as 'sc' (master = local[*], app id = local-1650102324143).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.2.1
/_/
Using Scala version 2.12.15 (OpenJDK 64-Bit Server VM, Java 1.8.0_312)
Type in expressions to have them evaluated.
Type :help for more information.
scala> :quit프로젝트 생성하기
Scala 를 선택하고, JDK 버전은 8 로 선택한다.
확인한 Scala 버전을 설정해 준다.
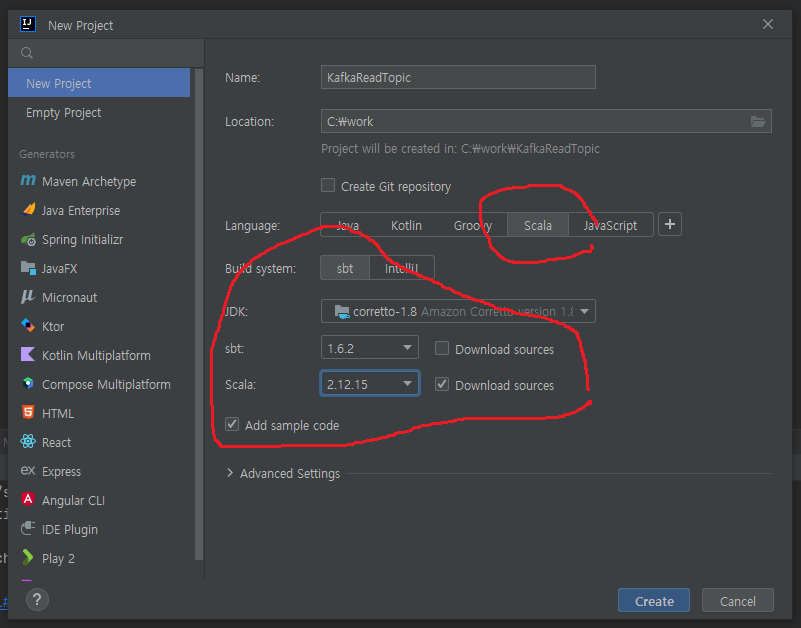
추가설정하기
여기 를 참조해 설정해 준다.
프로젝트를 실행하면, jar 생성 후, 서버에 복사해 주고,
Spark-Submit 까지 자동으로 해준다.
우선은 정상실행만 확인해 본다.
/home/spark/spark-3.2.1-bin-hadoop3.2/bin/spark-submit --master local --deploy-mode client --name Unnamed file://$HOME/ReadTopic.jar의존성 추가
build.sbt 에 의존성을 추가해 준다.
ThisBuild / version := "0.1.0-SNAPSHOT"
ThisBuild / scalaVersion := "2.12.15"
val sparkVersion = "3.2.1"
libraryDependencies ++= Seq(
"org.apache.spark" %% "spark-core" % sparkVersion,
"org.apache.spark" %% "spark-sql" % sparkVersion
)
lazy val root = (project in file("."))
.settings(
name := "ReadTopic"
)Scala class 수정
Main.scala 클래스를 수정해 준다.
import org.apache.spark.sql.SparkSession
object ReadTopic {
def main(args: Array[String]) {
val kafkaBrokers = "test.skyer9.pe.kr:9092"
val kafkaTopic = "exam"
val spark = SparkSession.builder()
.master("local[1]")
.appName("Test")
.getOrCreate()
val df = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest") // From starting
.load()
df.printSchema()
}
}패키지를 인식하지 못하면 프로젝트를 닫았다 다시 열어준다.
추가설정하기
패키지 org.apache.spark:spark-sql-kafka-0-10_2.12:3.2.1 가 추가되어야 한다.
/home/spark/spark-3.2.1-bin-hadoop3.2/bin/spark-submit --master local --deploy-mode client --name Remote --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.2.1 file://$HOME/ReadTopic.jar프로젝트 실행하기
key-value 형식으로 데이타가 수신된다.
root
|-- key: binary (nullable = true)
|-- value: binary (nullable = true)
|-- topic: string (nullable = true)
|-- partition: integer (nullable = true)
|-- offset: long (nullable = true)
|-- timestamp: timestamp (nullable = true)
|-- timestampType: integer (nullable = true)화면에 출력하기
IntelliJ 콘솔에서 한글이 깨지는 것은 신경쓸 필요없다.
(IntelliJ 문제)
서버에서 직접 실행해 보면 정상적으로 출력된다.
val kafkaBrokers = "test.skyer9.pe.kr:9092"
val kafkaTopic = "json_topic"
val spark = SparkSession.builder()
.master("local[1]")
.appName("Test")
.getOrCreate()
val df = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest") // From starting
.load()
val jsonStringDF = df.selectExpr("CAST(value AS STRING)")
val schema = new StructType()
.add("dt",StringType)
.add("msg",StringType)
val jsonDF = jsonStringDF.select(from_json(col("value"), schema).as("data"))
.select("data.*")
jsonDF.writeStream
.format("console")
.outputMode("append")
.start()
.awaitTermination() // 입력을 계속 기다림hadoop 에 저장하기
hadoop fs -rm -r /streaming/checkpointLocation
hadoop fs -rm -r /streaming/out/*
hadoop fs -mkdir -p /tmp
hadoop fs -chmod 777 /tmp
hadoop fs -mkdir -p /streaming/out
hadoop fs -mkdir -p /streaming/checkpointLocation jsonDF.writeStream
.format("com.databricks.spark.csv")
.outputMode("append")
.option("path", "hdfs://localhost:9000/streaming/out")
.option("checkpointLocation", "hdfs://localhost:9000/streaming/checkpointLocation")
.start()
.awaitTermination()hadoop 에 parquet(파케이) 포멧으로 저장하기
hadoop fs -rm -r /streaming/checkpointLocation
hadoop fs -rm -r /streaming/out/*
hadoop fs -mkdir -p /streaming/out
hadoop fs -mkdir -p /streaming/checkpointLocation jsonDF.writeStream
.format("parquet")
.outputMode("append")
.option("path", "hdfs://localhost:9000/streaming/out")
.option("checkpointLocation", "hdfs://localhost:9000/streaming/checkpointLocation")
.start()
.awaitTermination()hive 에서 데이타 읽기
hive
hive (default)> CREATE EXTERNAL TABLE tbl_weblog (
dt string,
msg string
)
STORED AS PARQUET
LOCATION "hdfs://localhost:9000/streaming/out";
hive (default)> select * from tbl_weblog;
hive (default)> select * from tbl_weblog order by dt desc limit 10;