Kafka 는 왜 빠를까?
Kafka 는 다른 큐 관리 시스템이 메모리 기반으로 운영되는 것과 달리 디스크 기반으로 운영됩니다.
디스크 기반으로 운영되기에 대량의 메시지를 보관할 수 있고, 예측불가능한 서버 다운에도 대처할 수 있는 장점이 생겼습니다.
그런데…
디스크 기반이면 느려야 하는데 … 왜 빠르다는 이야기가 나올까요?
Zero Copy
Traditional Data Transfer
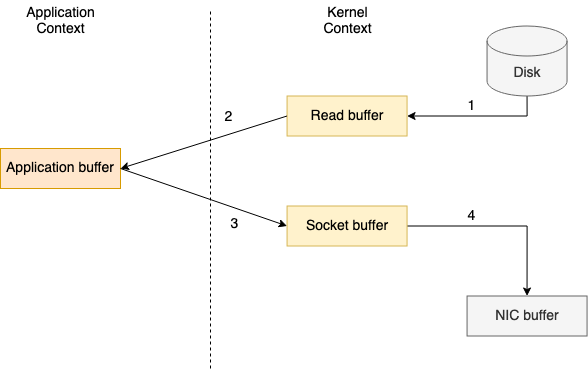
일반적인 애플리케이션은 데이타를 메모리에 올린 후 전송합니다.
Zero Copy Data Transfer
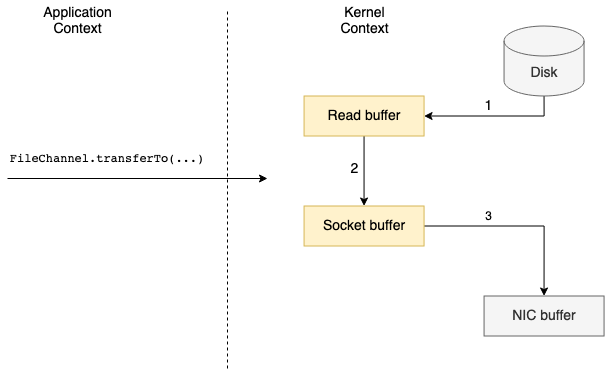
Kafka 는 애플리케이션에 데이타를 올리는 대신, 디스크에서 데이타를 읽음과 동시에 네트워크에 전송합니다.
How to Zero Copy
Kernel 명령어 중 sendfile() 함수를 이용함으로 해서,
앱이 사용하는 메모리에 데이타를 올리지 않고,
즉시 네트워크에 데이타가 전송됩니다.
SSL enabled??
암호화를 위해 SSL 을 활성화 하면 어떻게 될까?
더이상 Zero Copy 의 이점을 받을 수 없고,
애플리케이션 메모리에 파일을 올려야 합니다.
Page Cache
Linux 파일 작성 명령이 있을 때,
즉시 디스크에 파일을 저장하는 대신 Page Cache 라는 공간에 저장후,
지연하여 파일을 저장합니다.
또한, 하나의 Consumer 에 의해 읽기 요청이 왔을 때,
역시 Page Cache 에 저장 후,
동일한 데이타 요청이 왔을 때 메모리에 적재되어 있는 데이타를 전송합니다.
따라서 OS 메모리를 충분히 남겨 놓는게 중요합니다.
Low-Latency IO
Kafka 는 Sequential IO 를 이용해 디스크 읽기 속도를 증가시킵니다.
Sequential IO
디스크의 읽기 속도는 실제 데이타를 읽는 속도가 아니라,
데이타의 위치를 찾는 시간(Seek Time) 에 의해 디스크 읽기 속도가 지연됩니다.
Kafka 는 데이타를 순차적으로 저장하기에,
Seek Time 을 최소화 할 수 있습니다.
How to Sequential IO
파일의 저장 위치는 OS 에 의해 결정되는데,
어떻게 Kafka 의 Sequential IO 가 가능할까?
Kafka 는 Sequential IO 를 보장하는 것이 아니라,
대부분의 경우에 Sequential IO 로 작동하도록 운영됩니다.
Kafka 는 거대한 파일들(각각 디폴트로 1G) 에 데이타를 저장합니다.
그 파일들에 데이타를 저장하고,
삭제는 그 파일의 모든 데이타가 expire 되었을때만 진행됩니다.
그렇기에 파편화가 거의 발생하지 않습니다.
다만, 다른 앱에 의해 읽기/쓰기가 진행되고, 파편화가 진행되면,
Kafka 또한 파편화의 영향을 받게 됩니다.
따라서, 다른 앱의 영향을 받지 않는 독립적 파일 시스템에서,
Kafka 가 운영되는 것이 권장됩니다.
메시지 데이타가 커지면?
데이타 사이즈가 큰 메시지가 대량으로 큐에 올라오게 되면,
카프카 단독으로도 디스크 파편화가 발생하게 됩니다.
따라서 데이타 사이즈를 줄이는게 성능 유지에 도움이 됩니다.